This post is available in: Chinese
CoreOS is an important part of many container stacks. In this series of posts, we’re going to take a look at CoreOS, why it’s important, and how it works. If you don’t know anything about CoreOS already, don’t worry. We start at the beginning.
CoreOS is designed for security, consistency, and reliability.
- Automatic CoreOS updates are done using an active/passive dual-partition scheme to update CoreOS as a single unit, instead of using a package-by-package method. We go over this in detail later.
-
Instead of installing packages via yum or APT, CoreOS uses Linux containers to manage your services at a higher level of abstraction. A single service’s code and all dependencies are packaged within a container that can be run on a single CoreOS machine or many CoreOS machines in a cluster.
-
Linux containers provide similar benefits to complete virtual machines, but are focused on applications instead of entire virtualized hosts. Because containers don’t run their own Linux kernel or require a hypervisor, they have almost no performance overhead. The lack of overhead allows you to gain density which means fewer machines to operate and a lower compute spend.
CoreOS runs on almost any platform, including Vagrant, Amazon EC2, QEMU/KVM, VMware, OpenStack, and your own bare-metal hardware.
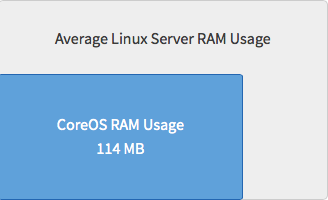
Because CoreOS is only designed to run application containers, many fewer system-level packages are required and installed. This means lower CPU use and more efficient memory (RAM) use as compared to a typical Linux server.
For example, here’s relative RAM usage:
In addition, CoreOS uses an active/passive dual partition scheme to boot from.
The system is booted into the root A partition:

The purpose of this will become clear in just a moment.
The CoreOS update philosophy is that frequent, reliable updates are critical to good security.
CoreOS minimizes the complexity of an update by combining each entity that normally needs to be updated:
- The operating system
- The application code
- Simple configuration
CoreOS updates are made consistent through use of FastPatch, an active-passive root partition scheme, which updates the entire OS as a single unit, instead of package by package.
All CoreOS machines have access to the public Update Service to receive updates as soon as they are available. The CoreOS Engineering team manages this service, including the promotion of versions from channel to channel and how quickly each update is released. These updates will always be available to all users, regardless of their status as CoreOS customers.
How an Update Works
This type of update has long been used for electronic firmware and is now used for most browser updates. Consider how frequently and seamlessly browsers like Chrome and Firefox update themselves automatically. The CoreOS team has, in fact, repurposed Google’s update engine, Omaha, also used in Chrome. Omaha uses an XML client-server protocol.
Initially, the system is booted into partition A (active) and CoreOS begins talking to the update service to find out about new updates. If there is an update available, it is downloaded and installed to root B.
Instead of updating a single package at a time, CoreOS downloads an entirely new root filesystem.
The OS update gets applied to partition B (passive) and, after reboot, partition now B becomes the active partition to boot from.
Here’s what that looks like:
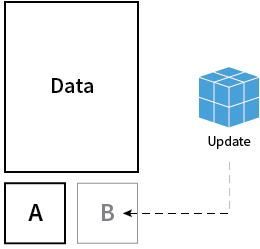

If the update is unsuccessful during the reboot, it rolls back to the previous boot partition.
With CoreOS, a system update is an atomic operation that can be easily rolled back.
The dual-partition scheme has many benefits over an in-place upgrade:
- Safe roll-back
- The previous, known-to-be-stable version of the operating system is still on the first partition. CoreOS has a built-in failsafe to revert to this partition if an upgrade results in an unstable state. This process can also be executed manually.
- Signed and verified
- Each boot partition is read-only, which makes it easy to verify that each download is complete and hasn’t been modified in transit.
- Extremely fast execution
- CoreOS boots extremely fast due to its small size. Executing an update requires a reboot which takes just a few seconds, meaning less interruption for your applications. Platforms that support kexec can skip the bootloader process, decreasing reboot time further.
Update Strategies and Automatic Updates
CoreOS comes with automatic updates enabled by default.
Each CoreOS cluster has a unique tolerance for risk and the operational needs. To meet everyone’s needs, there are four update strategies.
Let’s take a more detailed look at these update strategies:
-
best-effort:
- This strategy is the default. It checks whether the machine is part of a cluster. If it is, the
etcd-lock strategy is used; otherwise, the reboot strategy is used.
- This strategy is recommended for use in production clusters.
-
etcd-lock:
- This strategy mandates each machine acquires and holds a reboot lock before it is allowed to reboot. The main goal behind this strategy is to allow an update to be applied to a cluster quickly, without losing the quorum membership in etcd or rapidly reducing capacity for the services running on the cluster. The reboot lock is held until the machine releases it after a successful update.
-
reboot:
- This strategy reboots the machine as soon as the update gets installed on the passive partition.
- This strategy is good for machines that can only be rebooted at a certain time of the day — for example, for automatic updates in a maintenance window configured via cloud-config.
-
off:
- The machine will not be rebooted after a successful update install onto the passive partition.
- This strategy can be used for a local development environment where the control of reboots is in the user’s hands and in production clusters where you want your cluster machines to be rebooted at some certain time of day or night.
Automatic CoreOS reboots are done by locksmith, which is a reboot manager for the CoreOS update engine which uses etcd to ensure that only a subset of a cluster of machines are rebooting at any given time. locksmithd runs as a daemon on CoreOS machines and is responsible for controlling the reboot behaviour after updates.
The update strategy is defined in the update part of cloud-config file:
#cloud-config
coreos:
update:
reboot-strategy: best-effort
We’ll cover the specifics of cloud-config file in a future post.
CoreOS tracks three update channels:
CoreOS releases progress, in order, through each channel: alpha, to beta, then stable.
Each release on a lower channel is a release candidate for the next channel. Once a release is considered bug free, it is promoted, bit-for-bit, to the next channel.
It is possible to install from the stable channel and later switch to receiving updates from the beta or alpha channels quite easily. Similarly, it is possible to install from the beta channel and later switch to receiving updates from the alpha channel.
Note: It is not possible (without a fresh reinstall of OS) to install from the alpha channel and later switch to the beta or stable channels.
To switch a machine’s release channel, create an update.conf file:
$ sudo vi /etc/coreos/update.conf
Then set the desired release channel:
Now restart the update engine in order for it to pick up the changed channel:
$ sudo systemctl restart update-engine
When the next update check is done, the new release channel is applied.
CoreOS uses etcd, a service running on each machine, to handle coordination between software running on the cluster. For a group of CoreOS machines to form a cluster, their etcd instances need to be connected. We’ll cover etcd in more detail in a future post.
A discovery service, https://discovery.etcd.io, is provided free of charge to help connect etcd members together by storing a list of peer addresses, metadata and the initial size of the cluster under a unique address, known as the discovery URL.
You can generate a discovery URL very easily:
$ curl -w "\n" 'https://discovery.etcd.io/new?size=3'
This should produce an output like this:
https://discovery.etcd.io/6a28e078895c5ec737174db2419bb2f3
This works via providing all peers with a discovery token, and that’s how this service knows what to respond with.
This is used only for initial discovery and once a machine has located a peer, all further communication and coordination happens entirely within the cluster.
The discovery URL can be provided to each CoreOS machine via cloud-config, a minimal config tool that’s designed to get a machine connected to the network and join the cluster. The rest of this series will explain what’s happening behind the scenes, but if you’re trying to get clustered as quickly as possible, all you need to do is provide a fresh, unique discovery token in your cloud-config.
There are other etcd cluster bootstrapping methods:
You can read more about Cluster discovery in the documentation.
In this post, we looked at:
- How CoreOS is different from other Linux systems
- Atomic upgrades and release channels
- The basics of cluster discovery
In the next post in this series, we take a closer look at cloud-config, and etcd. We’ll also look at a few common cluster architectures.