This post is available in: Chinese`
This is the second post in a series looking at CoreOS.
In my last post, we looked at how CoreOS is different from other Linux systems, atomic upgrades and release channels, and the basics of cluster discovery.
In this post, we take a closer look at cloud-config and etcd. We’ll also look at a few common cluster architectures.
Cloud-config allows you to declaratively customize various OS-level items, such as network configuration, user accounts, and systemd units (which we’ll cover the next post). This came from Ubuntu and was modified a bit to fit the needs of CoreOS.
At the core of every CoreOS cluster machine, there is the bootstrap mechanic coreos-cloudinit. The coreos-cloudinit program the cloud-config file when it configures the OS after startup or during runtime.
What Is Cloud-Config Anyway?
It all starts with the cloud-config file, which uses YAML, with whitespace and new lines to delimit lists, associative arrays, and values.
Formating is crucial. Before you deploy your cloud-config on a node, you should validate it with the online tool provided by CoreOS.
A cloud-config file must start with #cloud-config, followed by an associative array which has zero or more keys.
Here are some frequently used keys:
-
coreos
- Handles all CoreOS specifics like
update strategy, etcd2, fleet, flannel, units and so on
-
write_files
- Directive defines a set of files to create on the local filesystem
-
ssh_authorized_keys
- Adds public SSH keys which will be authorized for the core user
Here’s an example cloud-config file:
#cloud-config
hostname: core-01
coreos:
update:
reboot-strategy: off
etcd2:
name: core-01
initial-advertise-peer-urls: http://127.0.0.1:2380
initial-cluster-token: core-01_etcd
initial-cluster: core-01=http://127.0.0.1:2380
initial-cluster-state: new
listen-peer-urls: http://0.0.0.0:2380,http://0.0.0.0:7001
listen-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001
advertise-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001
units:
- name: etcd2.service
command: start
- name: fleet.service
command: start
- name: docker-tcp.socket
command: start
enable: true
content: |
[Unit]
Description=Docker Socket for the API
[Socket]
ListenStream=2375
BindIPv6Only=both
Service=docker.service
[Install]
WantedBy=sockets.target
- name: docker.service
command: start
drop-ins:
- name: 50-insecure-registry.conf
content: |
[Unit]
[Service]
Environment=DOCKER_OPTS='--insecure-registry="0.0.0.0/0"'
write-files:
- path: /etc/conf.d/nfs
permissions: '0644'
content: |
OPTS_RPC_MOUNTD=""
ssh_authorized_keys:
- ssh-rsa 121313dqx1e123e12… user@my_mac
For more information about the cloud-config configuration parameters, see the documentation.
etcd is an open source, distributed, key-value store that provides a reliable way to store data across a cluster of machines.
etcd runs on each etcd cluster’s central services machine (don’t worry, we’ll explain this later in the post) and tolerates machine failure, including failure of the leader (a new leader will be elected if that happens).
Data is replicated across etcd nodes using the Raft consensus algorithm. Consensus is a fundamental problem in fault-tolerant distributed systems. Consensus involves multiple servers agreeing on values. Once they reach a decision on a value, that decision is final.
Deis uses etcd to store its data. Kubernetes (an open source orchestration system for containers) uses etcd to store its data too.
Optimal etcd Cluster Size
The recommended etcd cluster size is three, five, or seven. Although a larger cluster provides better fault tolerance, the write performance is reduced because data needs to be replicated to more machines.
In most cases, three or five members in a cluster is enough.
It is recommended to have an odd number of members in a cluster. Having an odd number of members doesn’t change the number needed for majority, but you gain a higher tolerance for failure by adding the extra member.
You can see this in practice when comparing even and odd-sized clusters:
Fault Tolerance Table
| Cluster Size |
Majority |
Failure Tolerance |
| 1 |
1 |
0 |
| 3 |
2 |
1 |
| 4 |
3 |
1 |
| 5 |
3 |
2 |
| 6 |
4 |
2 |
| 7 |
4 |
3 |
| 8 |
5 |
3 |
As you can see, adding another member to bring the size of cluster up to an odd size is always worth it.
During a network partition, an odd number of members also guarantees that there will almost always be a majority of the cluster that can continue to operate and be the source of truth when the partition ends.
For more about the etcd discovery see the documentation.
An example of etcd central services machines setup:
#cloud-config
coreos:
etcd2:
# generate a new token for each unique cluster from https://discovery.etcd.io/new
discovery: https://discovery.etcd.io/60887e46255f4efew37077ccf12b5f06a54a
initial-advertise-peer-urls: http://$private_ipv4:2380
# listen on both the official ports and the legacy ports
# legacy ports can be omitted if your application doesn't depend on them
listen-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001
listen-peer-urls: http://$private_ipv4:2380,http://$private_ipv4:7001
data-dir: /var/lib/etcd2
The https://discovery.etcd.io/new?size=3 URL was used, so the initial etcd cluster size must be 3 machines.
Proxy Mode
As you bootstrap a separate etcd cluster for central services, your worker machines need to connect to that etcd cluster to register themselves as a cluster member and to be able to receive deployed cluster fleet units, get OS updates control, and so on.
The easiest way to do that is to run each cluster worker node in the etcd proxy mode instead of starting etcd server locally.
Running etcd as a proxy allows for easy discovery of etcd on your network, because it can run on each machine as a local service. In this mode, etcd acts as a reverse proxy and forwards client requests to an active etcd node. Because the etcd proxy does not participate in the consensus replication of the etcd cluster, it neither increases the resilience nor decreases the write performance of the etcd cluster.
Services that needs to talk to etcd can connect to localhost.
etcd currently supports two proxy modes: readwrite and readonly.
The default mode is readwrite, which forwards both read and write requests to the etcd cluster.
The proxy rotates through the list of cluster members periodically to avoid forwarding all traffic to a single member.
An example of etcd proxy setup:
#cloud-config
coreos:
etcd2:
listen-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001
advertise-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001
discovery: https://discovery.etcd.io/60887e46255f4efew37077ccf12b5f06a54a
proxy: on
This accepts client connectons via localhost and forwards them to the etcd central services cluster via this discovery URL:
https://discovery.etcd.io/60887e46255f4efew37077ccf12b5f06a54a
For more about the etcd proxy see the documentation.
Depending on the size of your cluster and how it’s going to be used, there are a few common cluster architectures that must be followed.
It is strongly recommended that you set aside a fixed number of machines to be dedicated to running etcd central cluster services and a separate fixed number of machines for the distributed controllers for applications like Deis, Kubernetes, Mesos, and OpenStack.
Separating out these services into fixed number machines allows you to make sure they are distributed across datacenter cabinets and availability zones and setting up static networking to allow for easy cluster bootstrapping.
If you’re worried about relying on the discovery service, this architecture will remove your worries.
Then you can set up your worker machines to be connected to central services. In such a setup you can scale up/down your machines to meet your demand and not to be worried about breaking quorum of your etcd cluster.
For more information about setting up different cluster architectures with provided cloud-config files, see the documentation.
Let’s go into a few examples.
Docker Dev Environment on a Laptop
If you’re developing locally, but plan to run containers in production, it helps to mirror that environment locally.
This can easily be done by running Docker commands on your laptop to control a CoreOS VM in VMware Fusion or VirtualBox.
Here’s a laptop development environment with a CoreOS VM:
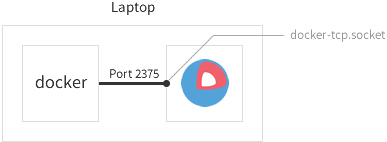
An Easy Development and Testing Cluster
Here’s a CoreOS cluster optimized for development and testing:
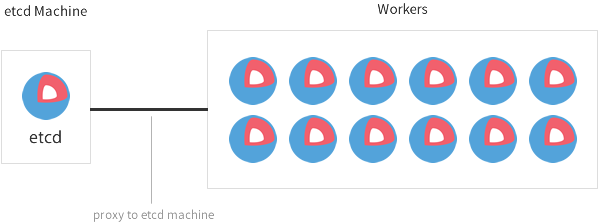
A setup like this is great for running your development, testing, and staging environments on bare metal or cloud VM instances.
When you’re first getting started with CoreOS, it’s common to frequently tweak your cloud-config. This requires booting, rebooting, and destroying many machines. Instead of being slowed down by generating new discovery URLs and bootstrapping etcd, it’s easier to start a single etcd node. This way you are free to boot as many machines as you’d like that read from the etcd node.
All the features of fleet, locksmith, and etcdctl continue to work properly, but connect to the etcd cluster via etcd proxy instead of using the worker’s local etcd instance. Since etcd is running only in a proxy mode on all of the worker machines, you gain a little extra CPU and RAM.
This environment is now set up for optimal performance.
Pull the plug on a machine and watch fleet reschedule the units, max out the CPU, and so on!
A Production Cluster With Central Services
A CoreOS cluster separated into central services and workers:
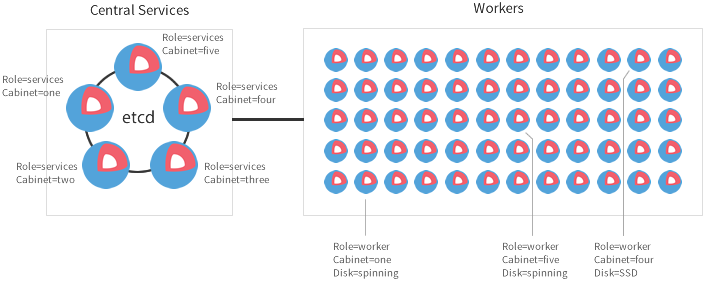
This setup is good for production. The cluster is separated into central services and workers.
For large clusters, it’s recommended to set aside three to five machines to run central services.
After those are set up, you can boot as many workers as you want.
Each of the workers uses the distributed etcd cluster on the central machines via local etcd proxies.
fleet is used to bootstrap both the central services and jobs on the worker machines by taking advantage of machine metadata and global fleet units. We cover this in the next post!
Note: If you have Deis, Kubernetes, or other services which need dedicated machines, do not put those services onto etcd cluster machines. Instead, dedicate a fixed number machines for them also. It is not recommended to use etcd cluster machines to run anything other than etcd services.
In this post, we looked at:
- The cloud-config file
- Why the ideal etcd cluster size is an odd number
- Running etcd in proxy mode
- Some common etcd cluster setups
In the next post we take a look at systemd and fleet in a bit more detail.